
数据库与信息系统研究室







- 1999
- 2000
- 2003
- 2003
- 2006
- 2007
- 2009
- 2011
- 2013
- 2013
- 2013
- 2013
- 2013
- 2014
- 2014
- 2014
- 2014
- 2015
- 2015
- 2016
- 2017
- 2017
- 2017
-
 [国家高技术研究发展计划(863计划)]制造类型企业的自我诊断与评价方法研究
[国家高技术研究发展计划(863计划)]制造类型企业的自我诊断与评价方法研究项目探讨了实现企业评价与诊断的思想、方法和技术路线,并利用专家系统、数据仓库和数据挖掘等技术,设计并实现了企业评价与诊断软件原型系统。
-
 [教育部骨干教师资助计划]知识发现关键技术研究
[教育部骨干教师资助计划]知识发现关键技术研究项目主要研制基于数据仓库星型模式和雪片模式下的通用知识发现算法,重点研究事实表中多个测度数据异常变化之间的关系,以及测度与维度之间的数据潜在联系。
-
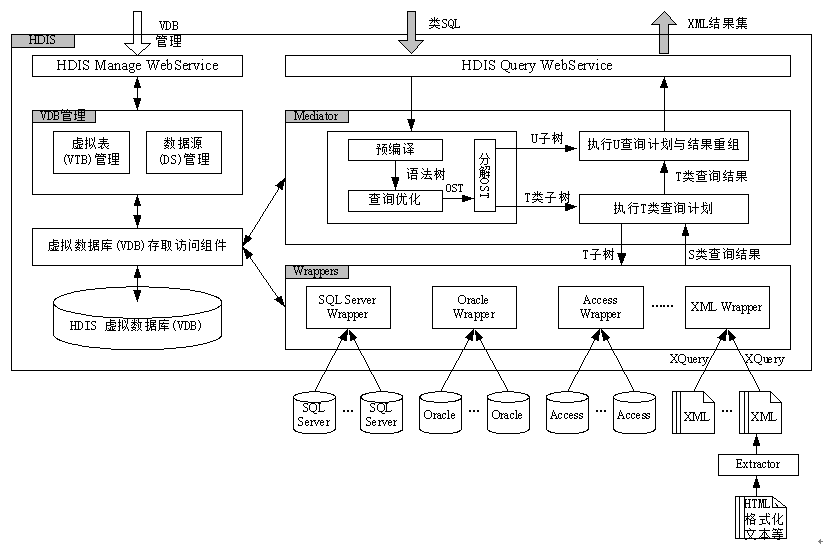 [天津市科技发展计划]基于Mediation的Web异构数据集成研究
[天津市科技发展计划]基于Mediation的Web异构数据集成研究项目采用Mediation方法对Web异构数据集成的相关技术进行研究,设计与实现了Mediator软件组件,用户使用该组件可以访问Web站点上经过包装的分布式异构数据。项目设计了三种异构数据集成的方式,即:PUSH(查询下推方式)、PULL(查询结果预抽取方式)和HYBRID(混合模式),给出了两套基于Mediation的Web异构数据集成方案,并完成了HDIS和Exceed两个关系型通用数据集成原型系统。
-
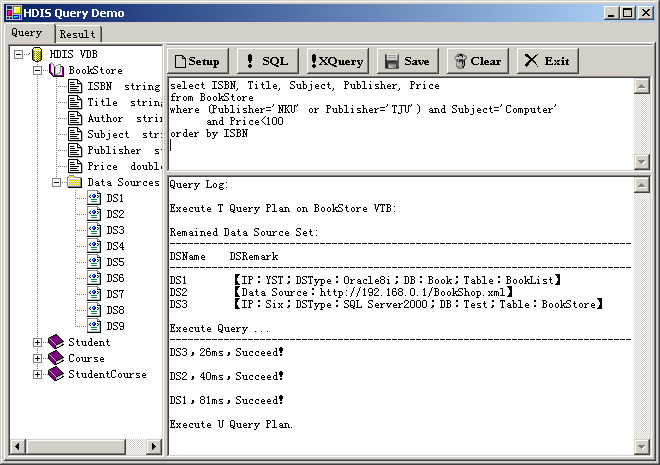 [天津市信息化办项目]基于Web的分布式异构数据集成平台的开发
[天津市信息化办项目]基于Web的分布式异构数据集成平台的开发项目采用Mediation方法,以Web数据集成技术为基础,以XML为数据格式,使用通用的包装器服务接口,提供了一个高效的同类数据源和关联数据源的集成解决方案。基于该方案成功开发了基于Web Services的Web数据集成中间件或Web集成平台原型系统。
-
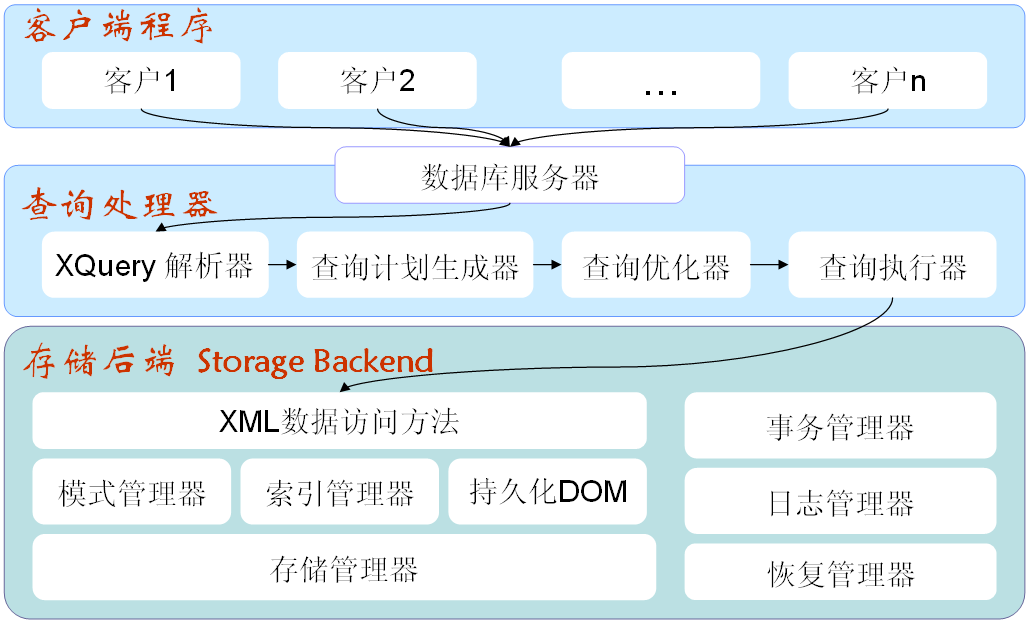 [天津市科技攻关项目]原生XML数据库技术研究与系统实现
[天津市科技攻关项目]原生XML数据库技术研究与系统实现项目研究了原生XML数据库的相关技术,包括存储策略、集合管理、索引结构、查询处理、数据更新策略等,设计并实现了一个具有自主知识产权的原生XML数据库管理系统XNative,该系统通过天津市软件评测中心的验收测试,并取得计算机软件著作权登记证书(2008SR09694),XNative系统的部分软件功能填补了国内同类软件的空白。
-
 [天津市应用基础与前沿技术研究计划]大规模数据集分布式存储技术研究
[天津市应用基础与前沿技术研究计划]大规模数据集分布式存储技术研究项目借鉴分布式文件系统、分布式数据库、数据网格等技术思想,重点研究大规模数据集的分布式存储体系结构和高效的数据索引方案,解决分布式数据集存储中数据集分布、安全控制与并发访问等理论和技术问题,提供可扩展的、高效的、高可靠的海量数据集存储策略和并发访问策略,以满足各个领域对分布式数据集的存储与访问需求。
-
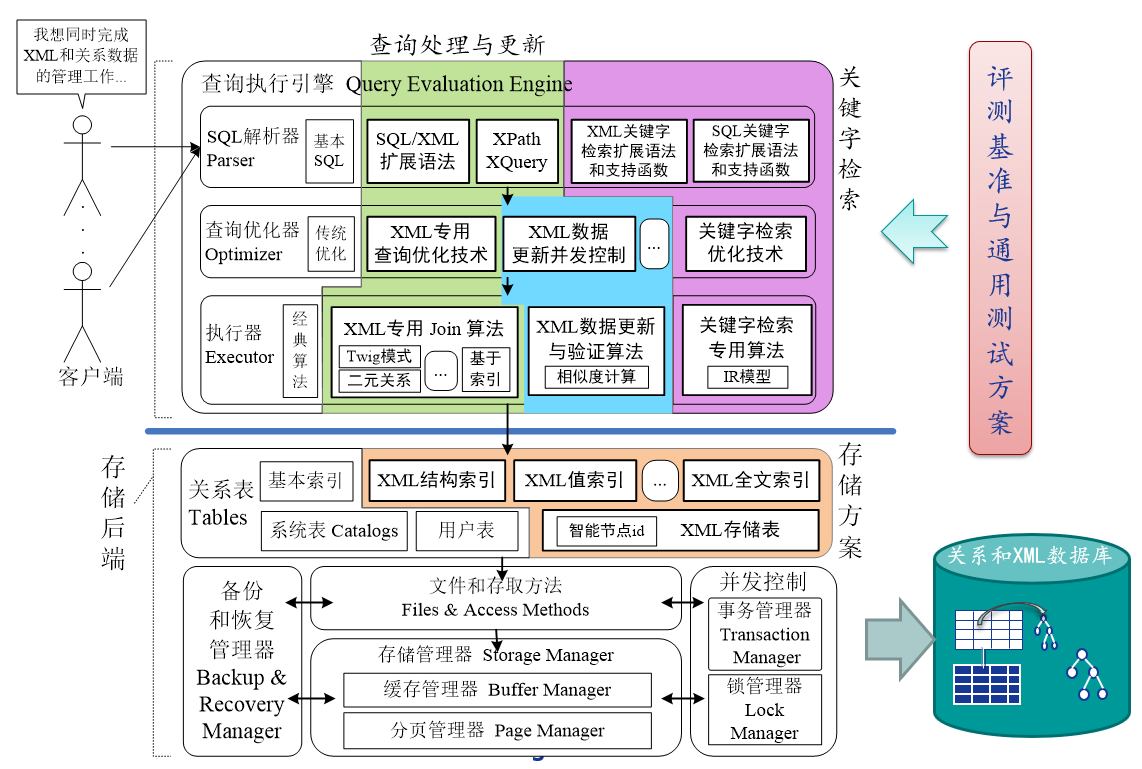 [国家高技术研究发展计划(863计划)]无缝集成关系数据库系统的纯XML引擎研制与关键技术研究
[国家高技术研究发展计划(863计划)]无缝集成关系数据库系统的纯XML引擎研制与关键技术研究项目研究了无缝集成关系数据库系统的纯XML引擎关键技术, 设计并实现了无缝集成关系数据库系统的纯XML引擎DiReX,制定了与关系数据库系统无缝集成的纯XML引擎评测基准。DiReX由XML数据存储、查询处理与优化、数据更新与验证以及关键字检索四个功能模块组成,依据W3C和ISO的相关标准在关系数据库PostgreSQL中无缝集成了XML数据管理功能,项目成果能够在与半结构化数据管理相关的科研领域和应用领域进行推广。
-
 [国家自然科学基金面上项目]云数据库查询模式集自动生成与检索关键技术研究
[国家自然科学基金面上项目]云数据库查询模式集自动生成与检索关键技术研究项目采用数据库与信息检索相结合的方法,设计了基于云数据库模式快速、准确检索云数据库的新方法。项目主要攻克了云数据库模式抽取、查询模式集自动生成和查询模式集检索排序等关键科学问题,为云数据库关键字检索打开了新的研究视野,为实现快速、准确检索云数据库提供了基础性研究。项目发表高水平论文18篇,完成发明专利4项,发表软件著作权2项。
-
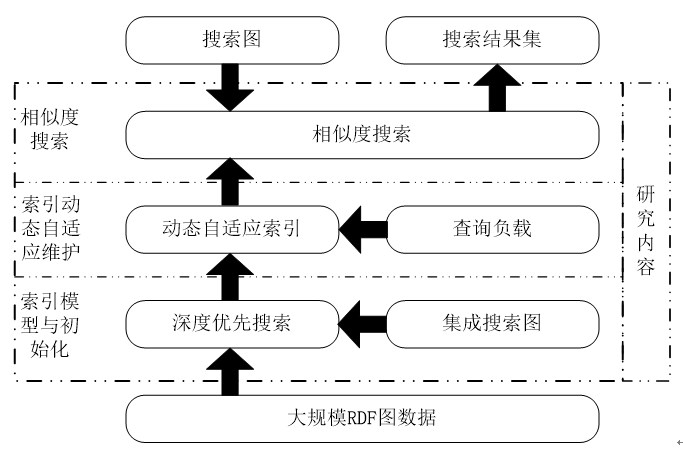 [天津市应用基础与前沿技术研究计划项目]面向语义网的大规模RDF图数据相似度搜索关键技术研究
[天津市应用基础与前沿技术研究计划项目]面向语义网的大规模RDF图数据相似度搜索关键技术研究针对于RDF为代表的有向标签图数据,研究并设计了给予图压缩技术的动态自适应索引模型,能够根据查询图的结构自适应调整结构并实现对查询图的100%覆盖率;研究并设计基于深度优先搜索策略的索引模型初始化方案,在两次深度优先遍历过程中实现图压缩并构建索引的初始化模型;研究并设计基于局部“双拟”关系的索引动态自适应更新算法以及基于自适应索引的子图匹配查询算法,可在接近线性的时间复杂度内实现子图匹配查询。
-
 [国家高技术研究发展计划(863计划)]基于语义的大数据存储体系结构及关键技术
[国家高技术研究发展计划(863计划)]基于语义的大数据存储体系结构及关键技术针对基于大数据的知识服务及应用需求,提出基于语义的大数据组织体系结构,通过研究支持语义大数据的非易失性存储器智能混合方案、分布式语义大数据原生存储与索引方案、语义大数据的分布式高性能分析处理、语义大数据的分布式查询和检索以及面向语义万维网的异构数据集成和融合,实现基于语义的大数据的新型高效存储结构、高效率数据访问和高性能知识服务,设计并实现基于语义的大数据智能存储、处理与服务原型系统,通过两个示范应用展示原型系统的可用性和高效性。
-
 [天津市支撑计划重点项目]云数据模式抽取与智能检索关键技术研究与应用
[天津市支撑计划重点项目]云数据模式抽取与智能检索关键技术研究与应用项目利用云数据模式,研究云数据模式抽取、用户检索意向分析及查询模式集自动生成等关键技术,提出支持多类型终端的快速、准确检索云数据的解决方案,并基于该方案,为政府、企事业单位用户提供通用的云数据智能检索服务,在移动智能终端开展示范应用。
-
 [天津市重大科技专项]面向多种类型大数据的实时检测与深度分析
[天津市重大科技专项]面向多种类型大数据的实时检测与深度分析(1)搭建了南开深海大数据智能辅助决策平台,支持多种类型的数据的清洗、融合与存储,并提供交互式的可视化分析结果;(2)实现基于主题模型的融合用户社交网络关系的意见挖掘与预测模型框架;设计并实现了实体搜索引擎的架构;(3)设计并实现能够同时支持MapReduce模式和流处理模式的大数据实时处理通用架构,利用GPU和多核处理器大大提高了实时处理性能。
-
 [教育部-中国移动科研基金]基于网络侧数据的用户特征提取与新业务受众预测研究
[教育部-中国移动科研基金]基于网络侧数据的用户特征提取与新业务受众预测研究项目针对中国移动高效运营数据业务的需求,以用户行为模型为依据,从网络、用户、终端等方面展开多个维度的深度解析,挖掘用户关键特征。项目以用户对不同数据业务的使用情况为切入点,分析移动数据业务特征以及与用户特征的关联关系,研究新业务受众预测方法,为业务推广、网络资源配置与网络规划提供坚实的数据支撑和科学依据。
-
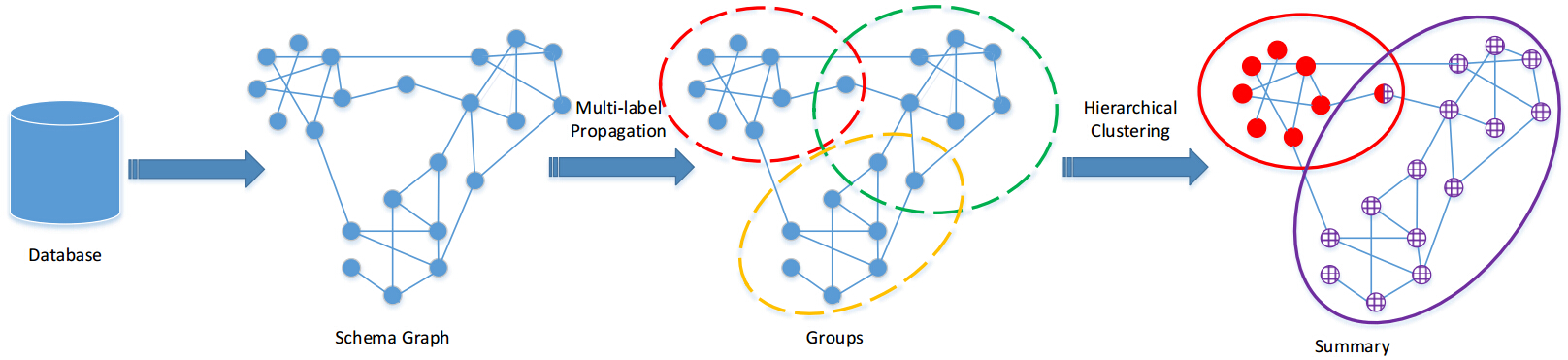 [天津市应用基础与前沿技术研究计划项目]基于模式图的云数据检索关键技术研究
[天津市应用基础与前沿技术研究计划项目]基于模式图的云数据检索关键技术研究项目研究基于云数据模式抽取与查询模式集自动生成的云数据智能检索技术,具体包括:1)发现数据表集合特征,抽取云数据的模式图;2)给出复杂模式图中模式节点的查询意向度评价算法;3)研究数据库候选查询模式集的描述与自动生成方法;4)提出符合候选查询模式特点的智能检索模型。
-
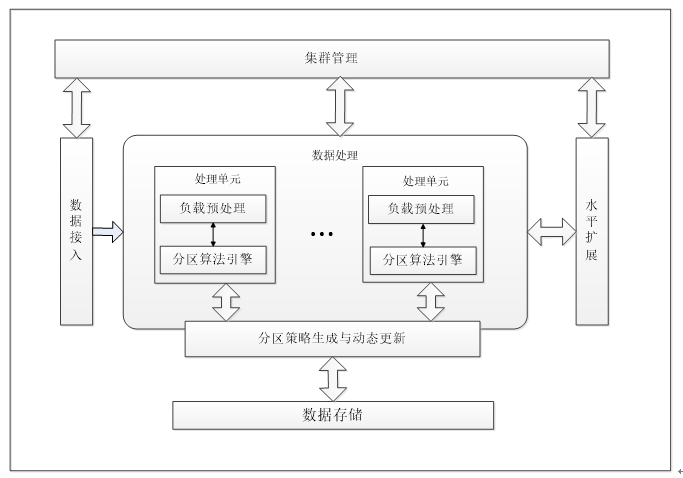 [天津市应用基础与前沿技术研究计划项目]云计算环境下面向大规模动态事务查询的数据分区策略
[天津市应用基础与前沿技术研究计划项目]云计算环境下面向大规模动态事务查询的数据分区策略项目针对云计算环境下面向大规模查询的数据分区策略问题展开研究,解决了从大规模动态事务查询中进行数据分区信息抽取与建模、云计算环境下面向实时事务查询的数据分区自动生成、基于事务执行代价模型的数据分区算法设计、数据分区策略的评价和验证问题,为数据库集群减少分布式事务,提高数据库群集中的事务吞吐量提供了基础研究方法。
-
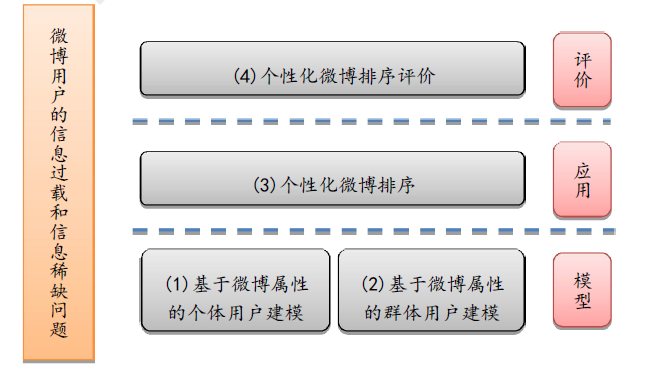 [国家自然科学青年基金项目]基于用户建模的个性化微博排序研究
[国家自然科学青年基金项目]基于用户建模的个性化微博排序研究项目针对微博的信息稀缺和信息过载等问题,通过处理海量用户的微博数据,建立个体用户模型和群体用户模型,构建了一个微博个性化排序评价的语料库,弥补目前用户建模研究缺乏对新型社交媒体微博支持的不足,同时探索了基于隐因子模型的个性化微博排序模型,推动微博服务个性化技术的发展。
-
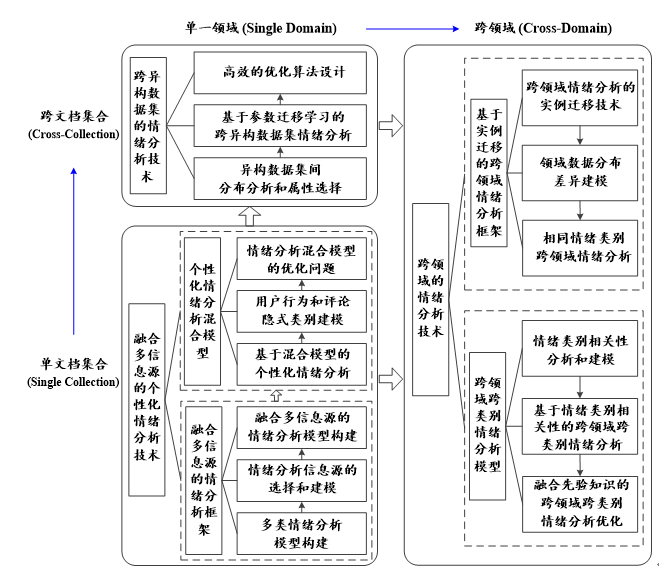 [国家自然科学青年基金项目]面向在线新闻评论的跨领域情绪分析关键技术研究
[国家自然科学青年基金项目]面向在线新闻评论的跨领域情绪分析关键技术研究项目围绕在线新闻评论的多类情绪预测问题,研究1)融合多种异构信息源的用户个性化和评论个性化情绪分析技术;2)利用含有已标注数据文档集的分类知识帮助没有标注数据文档集的情绪分析任务,实现跨异构数据集的在线新闻评论情绪预测;3)在源领域和目标领域情感类别集合相同和不同两种情境下,实现跨领域跨类别在线新闻评论情绪分析等。
-
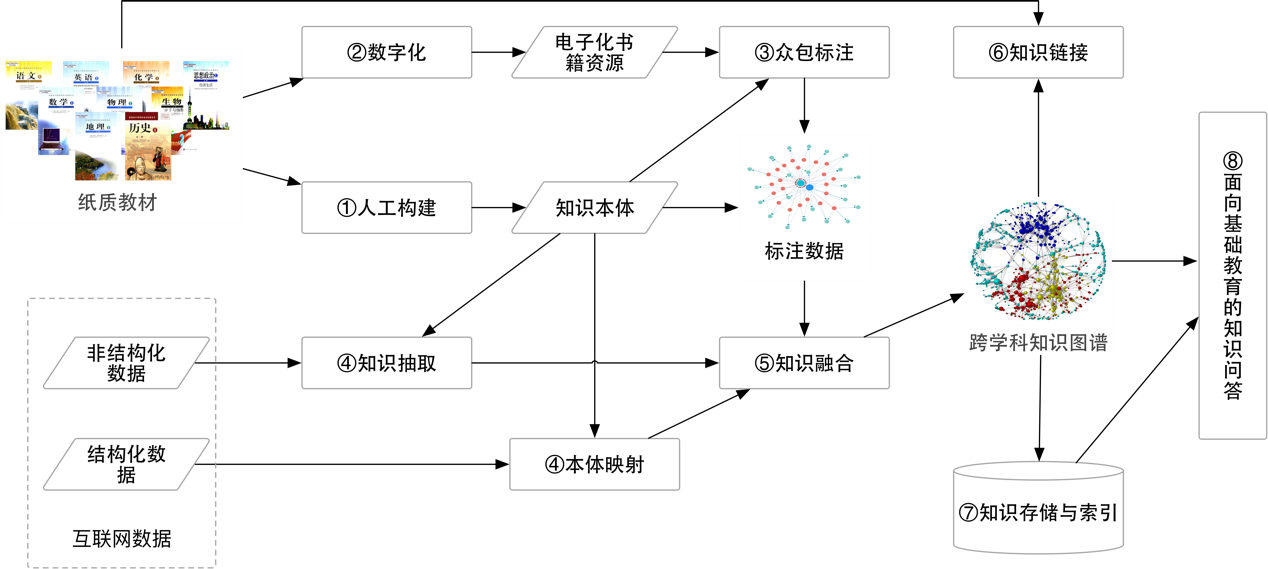 [国家高技术研究发展计划(863计划)项目]面向基础教育的海量知识库建设与构建关键技术及系统
[国家高技术研究发展计划(863计划)项目]面向基础教育的海量知识库建设与构建关键技术及系统项目面向我国信息技术服务于国家教育的重大现实需求,以海量知识库建设与构建关键技术为切入点,在基础教育中的知识分类体系、海量图书的数字化与结构化、面向基础教育的概念模型、概念属性与实例的自动抽取、知识记忆类问题求解等方面开展研究,研制出适用于基础教育的知识库系统。
-
 [教育部-中国移动科研基金]基于 Spark 技术的LTE 网络信令数据 实时分析系统研究
[教育部-中国移动科研基金]基于 Spark 技术的LTE 网络信令数据 实时分析系统研究项目主要针对中国移动LTE网络信令数据进行研究,并建立以网络质量分析与业务服务质量提升为目标的数据分析模型,构建了基于Spark技术的高效、稳定和健壮的实时网络信令数据分析系统,可以满足中国移动省公司范围内的网络优化和业务质量实时性分析的要求。
-
 [天津市自然科学青年基金]基于深度学习的网络新闻情感分析关键技术研究
[天津市自然科学青年基金]基于深度学习的网络新闻情感分析关键技术研究项目研究基于深度学习的网络新闻情感分析关键技术,具体内容包括:1)研究融合多种异构信息源的个性化网络新闻情绪分析解决方案;2)研究跨异构数据集的网络新闻情感分析解决方案;3)研究跨领域跨类别的网络新闻情感分析方案。
-
 [天津市自然科学青年基金]大数据流处理分析的关键技术研究
[天津市自然科学青年基金]大数据流处理分析的关键技术研究大数据流处理分析的关键技术研究,具体研究内容包括:1)离线(历史)大数据流/序列上的的关键事件及模式匹配。 2)实时高速数据流上的关键事件及模式匹配。 3)实时高速数据流上的特殊事件监测。对于以上研究内容,均考虑可能产生的嘈杂数据,并研发适用于多种不同应用场景的通用算法,使应答准确度与查询所需的时间空间复杂度达到最优平衡。
-
 [国家自然科学基金]文件流型大数据的分析模型构建与知识发现研究
[国家自然科学基金]文件流型大数据的分析模型构建与知识发现研究本项目拟针对文件流型大数据的特征,从基础数据层、分析映射层、交互聚集层和知识发现层四个层面,构建基于主题维的多层次分析模型,给出直接面向文件流型大数据的分析方法和典型知识发现算法,解决文件流型数据抽取、交互式聚集分析和增量知识发现等关键技术难题,提供准实用的文件流型大数据分析挖掘平台,以实现行业领域大数据价值增值过程。
-
 [国家自然科学青年基金项目]流模式下有标签图的略图问题研究
[国家自然科学青年基金项目]流模式下有标签图的略图问题研究项目拟对流模式下有标签图的压缩略图进行研究,使得到的略图能够保留图的结构信息,支持聚合点查询、聚合边查询,并作为一个黑箱支持已有的可达性查询、频繁项查询以及图模式匹配查询的查询算法,在存储代价、查询应答准确度及应答响应时间上达到最优平衡,以满足在线需求。
2021年10月14日上午9:00,“DBIS实验室实习生经验分享会”在计算机学院楼620室成功举办
4月28日,中共中央网络安全和信息化委员会办公室总工程师、全国信息安全标准化技术委员会常务副主任赵泽
4月28日,中共中央网络安全和信息化委员会办公室总工程师、全国信息安全标准化技术委员会常务副主任赵泽
2019年1月19日,“计算机体系结构南开青年论坛”在我院成功举办。此次活动由南开百度联合室承办,邀
“南开大学青年五四奖章”是南开大学共青团系统所授予的最高荣誉。在中国共产党成立百年暨五四运动102周
正值中国共产党成立100周年,为深入开展党史学习教育、促进和谐实验室建设,数据库与信息系统实验室(D
新学期开始,实验室将于每周四下午组织大家开展羽毛球和游泳等团建活动,并将择期举办实验室“砸六家”扑克
不经意间,又是一年春色归,校园蕙风轻轻,草树依依,各色的花开的正热闹。DBIS实验室希望能够让同学们
1024程序员节来临之际,DBIS实验室成功举办实验室开放日!DBIS实验室长期致力于大型数据库与信
2021年9月7日,实验室召开了2021年秋季学期开学动员大会。新学期,新目标,新起点,新征程。新同
6月17日下午,图数据分析小组完成了本学期最后一次的CS224W 2021冬季课程分享。CS224W
6月18日上午,实验室举办了2020-2021春季学期校内博士生和二年级研究生期末大组会,全体师生以

