数据库与信息系统研究室师生3篇论文被国际学术会议COLING 2022录用
COLING 2022(The 2022 International Conferenceon Computational Linguistics)于2022年10月12日至17日举办。计算语言学国际会议COLING 2022(是计算语言学和自然语言处理领域的重要国际会议,由ICCL(国际计算语言学委员会)主办,每两年一次,是CCF推荐的B类顶级会议。
下面是论文列表及介绍:
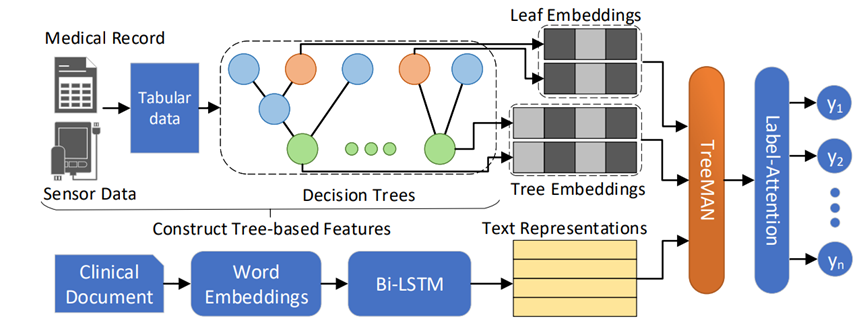
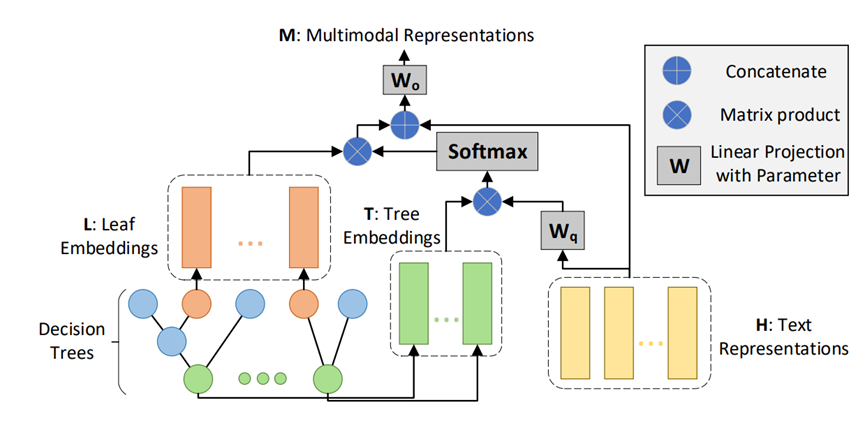
刘子晨,刘旭源,温延龙,赵国庆, 夏粉,袁晓洁, TreeMAN: Tree-enhanced Multimodal Attention Network for ICD Coding, COLING, 2022。
吴一可,赵钰,赵石顽,张莹,袁晓洁,赵国庆,蒋宁,Overcoming Language Priors in Visual Question Answering via Distinguishing Superficially Similar Instances,COLING,2022。
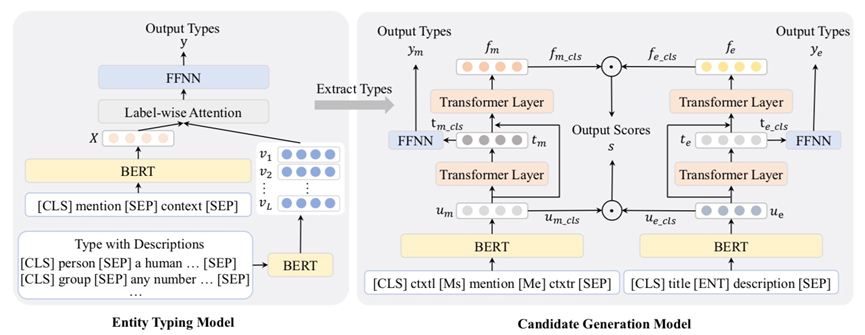
隋旭辉,张莹,宋珂慧,周宝航,赵国庆,Xin Wei,袁晓洁,Improving Zero-Shot Entity Linking Candidate Generation with Ultra-Fine Entity Type Information,COLING,2022。
1.论文题目:TreeMAN: Tree-enhanced Multimodal Attention Network for ICD Coding
作者:刘子晨,刘旭源,温延龙,赵国庆, 夏粉,袁晓洁
通讯作者:温延龙
录用会议/期刊:COLING 2022
论文概述:
ICD 编码旨在在出院时将疾病代码分配给电子健康记录 (EHR),这对于计费和临床统计至关重要。为了提高手动编码的有效性和效率,已经提出了许多方法来从临床记录中自动预测 ICD 代码。然而,以前的大多数工作都忽略了 EHR 中结构化医疗数据中包含的决定性信息,这些信息很难从嘈杂的临床记录中捕捉到。在本文中,我们提出了一种树增强的多模态注意力网络(TreeMAN),通过注意力机制通过基于树的特征增强文本表示,将表格特征和文本特征融合为多模态表示。基于树的特征是根据从结构化多模态医学数据中学习的决策树构建的,这些决策树捕获了有关 ICD 编码的决定性信息。我们可以将来自先前文本模型的相同多标签分类器应用于多模态表示来预测 ICD 代码。对两个 MIMIC 数据集的实验表明,我们的方法取得了最优效果。
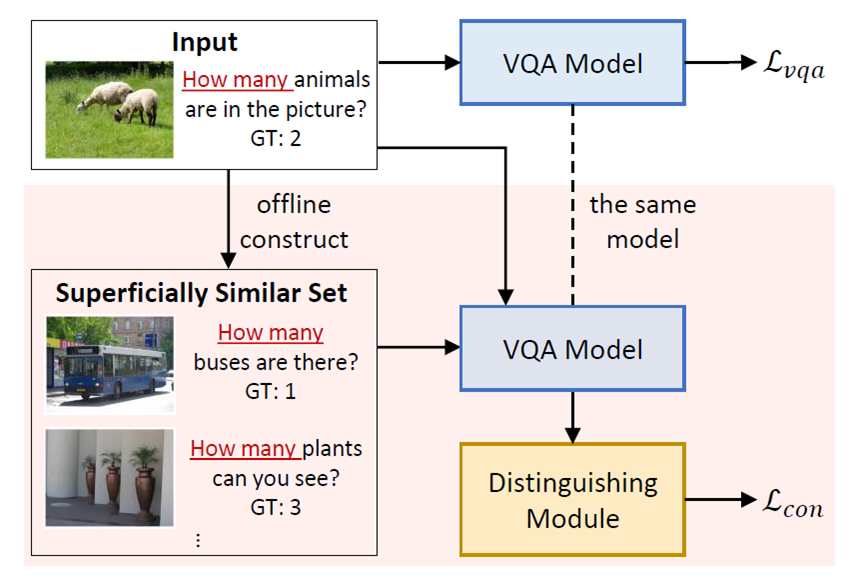
2.论文题目:Overcoming Language Priors in Visual Question Answering via Distinguishing Superficially Similar Instances
作者:吴一可,赵钰,赵石顽,张莹,袁晓洁,赵国庆,蒋宁
通讯作者:张莹
录用会议/期刊:COLING 2022
论文概述:尽管视觉问答(VQA)任务目前取得了很大的进展,现有的VQA模型没有真正理解输入,而是仍严重依赖于问题类型与其对应的频率最高的答案之间的表面相关性来进行预测,也就是利用语言偏置。在这篇论文中,我们定义具有相同问题类型但答案不同的训练样例为表面相似样例,并将语言偏置归因于VQA模型对此类样例的混淆。为了解决这个问题,我们提出了一个新的训练框架,显式地鼓励VQA模型区分表面相似实例。具体来说,对每个训练样例,我们首先构建一个包含该样例的表面相似样例的集合。然后我们运用提出的判别模块增加该样例和它的表面相似样例在答案空间中的距离。用这样的方法,VQA模型被迫进一步关注问题类型以外的其他输入部分,这有助于克服语言先验。实验结果表明,我们的方法在VQA-CP v2上达到了最先进的性能。
3.论文题目:Improving Zero-Shot Entity Linking Candidate Generation with Ultra-Fine Entity Type Information
作者:隋旭辉,张莹,宋珂慧,周宝航,赵国庆,Xin Wei,袁晓洁
通讯作者:张莹
录用会议/期刊:COLING 2022
论文概述:实体链接的目的是将模糊的实体提及与知识库中的参考实体对齐,在多种自然语言处理任务中起着关键作用。最近,零样本实体链接已经成为一个研究热点,它将提及的实体与未见过的实体联系起来,以挑战概括能力。对于这项任务,训练集和测试集来自不同的领域,因此,实体链接模型倾向于记忆训练集中频繁出现的实体的属性,往往会出现过拟合的情况。我们认为,通用的超细粒度类型信息可以帮助链接模型学习上下文的共性,提高其泛化能力,解决过拟合的问题。然而,在零样本实体链接设置中,任何类型信息都是不可用的,实体只能通过文本描述来识别。因此,我们首先从实体的文本描述中提取超细粒度的类型信息。然后,提出了一个分层的多任务模型,通过利用实体分类任务作为一个辅助的低级别任务,将提取的超细粒度类型信息引入到候选生成任务中,从而改善高级别的零样本实体链接候选生成任务。实验结果证明了利用超细粒度实体类型信息的有效性,我们提出的方法取得了最先进的性能。